Image par Marta Simon de Pixabay
Introduction
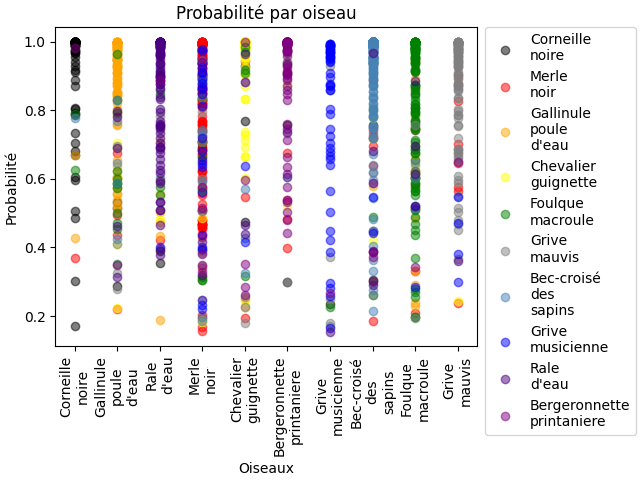
Notre projet consiste à classifier des oiseaux en fonctions de leur chant. Il faut donc un algorithme capable d’apprendre, qu’on appelle le machine learning. Ce dernier définissant plusieurs catégories d’algorithmes différents :
- Apprentissage supervisé
- Apprentissage non supervisé
- Apprentissage semi-supervisé
- Apprentissage par renforcement
L’algorithme supervisé utilise un jeu de données connu et étiqueté, c’est à dire que l’on sait à quoi correspond notre donnée. Son but est d’utiliser ces données afin de pouvoir prédire des résultats sur des nouvelles données inconnues. Pour y arriver, l’algorithme passe par une étape d’entrainement. L’apprentissage supervisé se distingue par l’apprentissage de régression et de classification. Des algorithmes connus de l’apprentissage supervisé sont : réseau de neurone, random forest, linear régression… C’est exactement ce dont on a besoin !
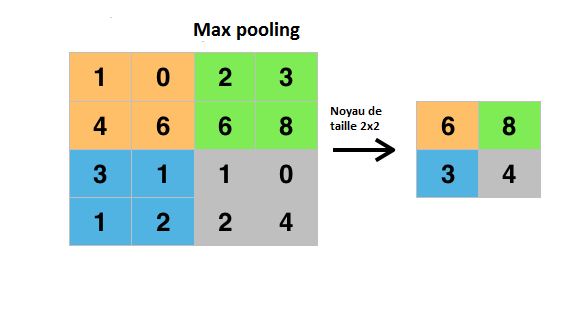
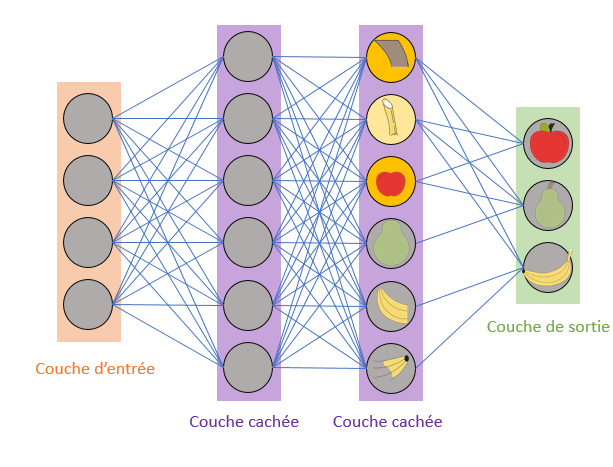
Nous avons ainsi choisi comme algorithme le réseau de neurone convolutif.
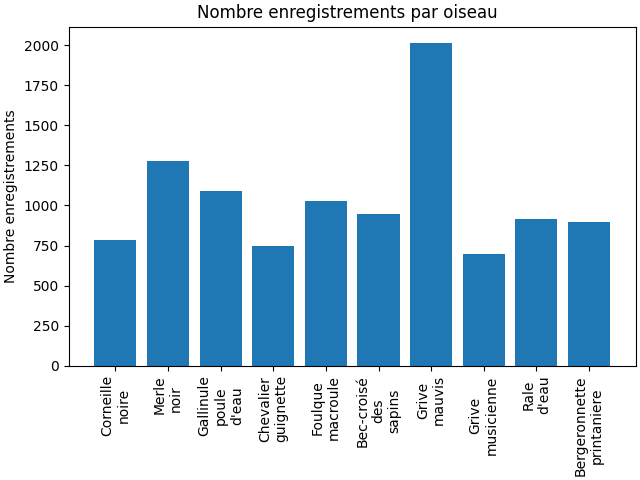
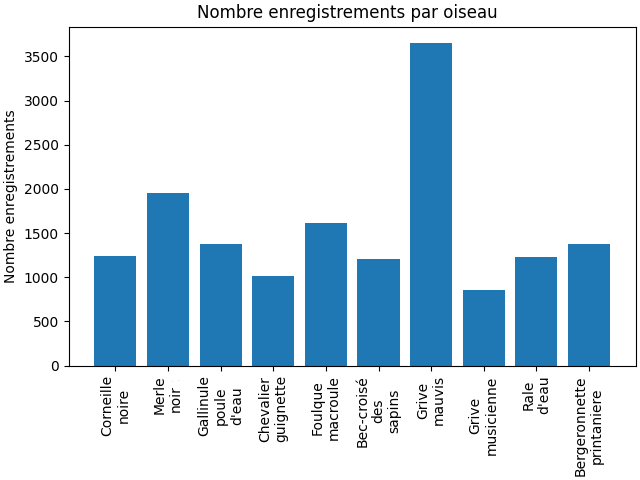
Mais avant de commencer à entrainer notre modèle, il nous faut des données, beaucoup de données, ainsi qu’un bon traitement (pre-processing). Nous avons suivi plusieurs étapes lors de ce traitement :
- Collection de données
- Nettoyage des données
- Transformation des données